
sanger-tol/readmapping v1.1.0 - Hebridean Black 1.1.0
 View on GitHub
View on GitHub![]()
![]()
Introduction
sanger-tol/readmapping is a bioinformatics best-practice analysis pipeline for mapping reads generated using Illumina, HiC, PacBio and Nanopore technologies against a genome assembly.
The pipeline is built using Nextflow, a workflow tool to run tasks across multiple compute infrastructures in a very portable manner. It uses Docker/Singularity containers making installation trivial and results highly reproducible. The Nextflow DSL2 implementation of this pipeline uses one container per process which makes it much easier to maintain and update software dependencies. Where possible, these processes have been submitted to and installed from nf-core/modules in order to make them available to all nf-core pipelines, and to everyone within the Nextflow community!
On merge to dev and main branch, automated continuous integration tests run the pipeline on a full-sized dataset on the Wellcome Sanger Institute HPC farm using the Nextflow Tower infrastructure. This ensures that the pipeline runs on full sized datasets, has sensible resource allocation defaults set to run on real-world datasets, and permits the persistent storage of results to benchmark between pipeline releases and other analysis sources.
Pipeline summary
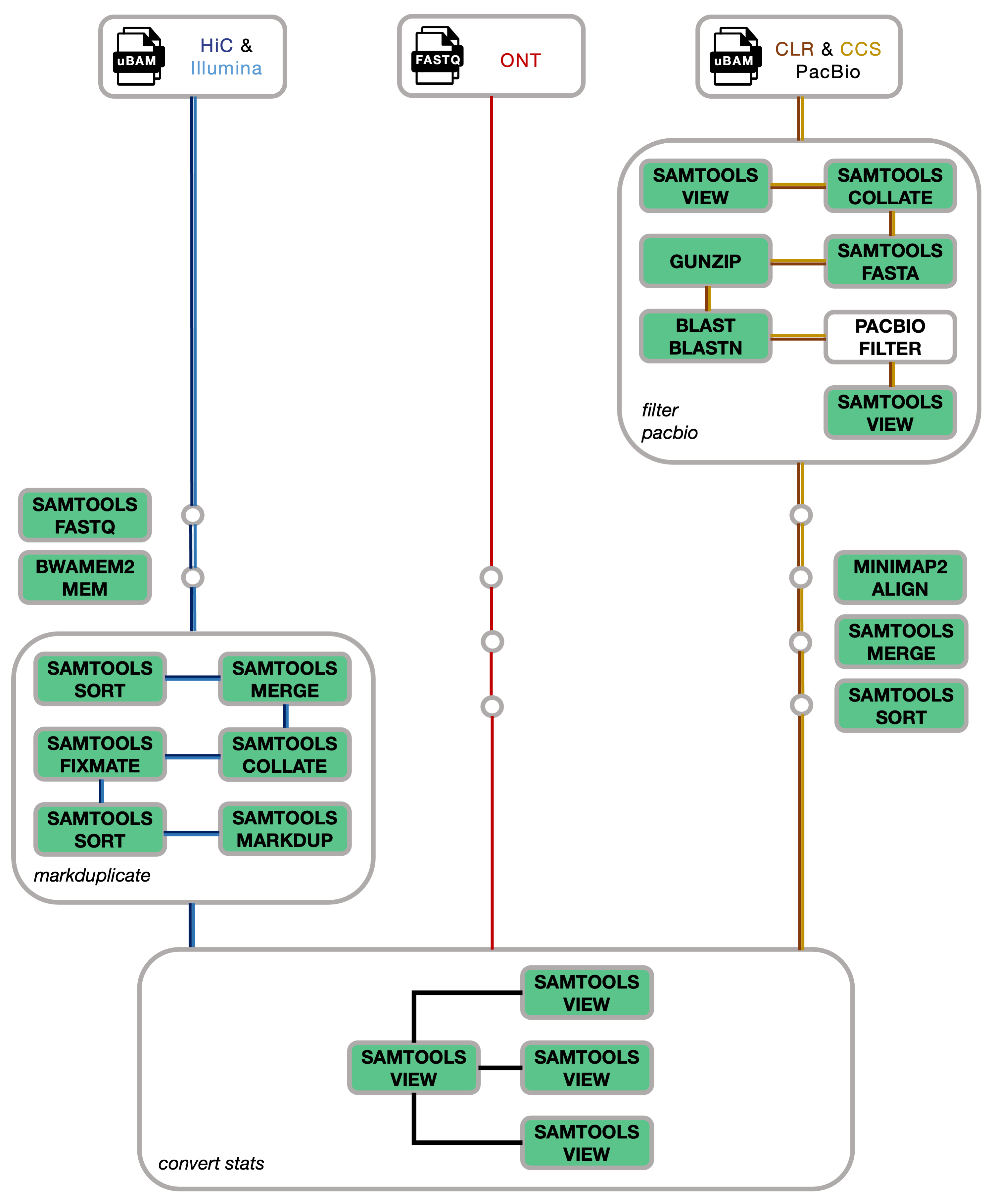
Quick Start
-
Install
Nextflow(>=22.10.1) -
Install any of
Docker,Singularity(you can follow this tutorial),Podman,ShifterorCharliecloudfor full pipeline reproducibility (you can useCondaboth to install Nextflow itself and also to manage software within pipelines. Please only use it within pipelines as a last resort; see docs). -
Download the pipeline and test it on a minimal dataset with a single command:
nextflow run sanger-tol/readmapping -profile test,YOURPROFILE --outdirNote that some form of configuration will be needed so that Nextflow knows how to fetch the required software. This is usually done in the form of a config profile (
YOURPROFILEin the example command above). You can chain multiple config profiles in a comma-separated string.- The pipeline comes with config profiles called
docker,singularity,podman,shifter,charliecloudandcondawhich instruct the pipeline to use the named tool for software management. For example,-profile test,docker. - Please check nf-core/configs to see if a custom config file to run nf-core pipelines already exists for your Institute. If so, you can simply use
-profilein your command. This will enable eitherdockerorsingularityand set the appropriate execution settings for your local compute environment. - If you are using
singularity, please use thenf-core downloadcommand to download images first, before running the pipeline. Setting theNXF_SINGULARITY_CACHEDIRorsingularity.cacheDirNextflow options enables you to store and re-use the images from a central location for future pipeline runs. - If you are using
conda, it is highly recommended to use theNXF_CONDA_CACHEDIRorconda.cacheDirsettings to store the environments in a central location for future pipeline runs.
- The pipeline comes with config profiles called
-
Start running your own analysis!
nextflow run sanger-tol/readmapping --input samplesheet.csv --fasta genome.fa.gz --outdir -profile
Credits
sanger-tol/readmapping was originally written by Priyanka Surana.
We thank the following people for their extensive assistance in the development of this pipeline:
- Matthieu Muffato for the text logo
- Guoying Qi for being able to run tests using Nf-Tower and the Sanger HPC farm
Contributions and Support
If you would like to contribute to this pipeline, please see the contributing guidelines.
For further information or help, don't hesitate to get in touch on the Slack #pipelines channel. Please create an issue on GitHub if you are not on the Sanger slack channel.
Citations
If you use sanger-tol/readmapping for your analysis, please cite it using the following doi: 10.5281/zenodo.6563577
An extensive list of references for the tools used by the pipeline can be found in the CITATIONS.md file.
This pipeline uses code and infrastructure developed and maintained by the nf-core community, reused here under the MIT license.
The nf-core framework for community-curated bioinformatics pipelines.
Philip Ewels, Alexander Peltzer, Sven Fillinger, Harshil Patel, Johannes Alneberg, Andreas Wilm, Maxime Ulysse Garcia, Paolo Di Tommaso & Sven Nahnsen.
Nat Biotechnol. 2020 Feb 13. doi: 10.1038/s41587-020-0439-x.
Version History
1.1.0 (earliest) Created 14th Nov 2023 at 11:55 by Matthieu Muffato
Merge pull request #60 from sanger-tol/release_1.1.0
Release 1.1.0
Frozen
 1.1.0
1.1.0c5d5612
 Creators and Submitter
Creators and Submitter
Views: 4326 Downloads: 865
Created: 14th Nov 2023 at 11:55
TagsThis item has not yet been tagged.
AttributionsNone
Related items

 https://orcid.org/0000-0002-7860-3560
https://orcid.org/0000-0002-7860-3560Informatics Infrastructure Team Lead, Sanger Institute, Tree of Life programme. Formerly Ensembl Compara, TreeFam, and eHive at EMBL-EBI.

The Tree of Life Programme uses DNA sequencing and cellular technologies to investigate the diversity and origins of life on Earth. Our research covers all eukaryotic organisms, which means all complex life with a nucleus in their cells – that is every animal, plant, fungi and protist on the planet.
We use Nextflow and are building our own pipelines following the nf-core methodology. All our pipelines are on GitHub, https://github.com/sanger-tol, and are then listed and documented at ...
Teams: Tree of Life Genome Assembly, Tree of Life Genome Analysis
We develop a suite of analysis pipelines that will run on every genome produced in Tree of Life, providing a central database of core results available for all.
Space: Sanger Tree of Life
Public web page: Not specified